Low light enhancement? Why do we need this in a year like 2024? Recently, Apple Vision Pro was released.In the first iteration of Apple Vision Pro, it did not perform well in low light conditions. It failed to calibrate the position of spatial computing.
What could be the solution for this situation? Obviously, an enhanced low light enhancement solution.
If we delve into low light enhancement, we can treat low light as noise. If we consider a well-lit image as ground truth, then the low-light image can be considered as a noisy version of that image.
So, if we want to remove noise, what comes to mind first? Of course, an autoencoder. An autoencoder is a combination of an encoder and a decoder. So, what’s the specialty of an autoencoder?
Anatomy of an autoencoder architecture

An autoencoder consists of an encoder, a decoder, and a feature vector.
In most classification neural networks, we know the last layer is a feature vector. Here, it’s the same. As shown in the figure above, the encoder can be made of different layers. The encoder tries to compress the details of the signal into a constant-length vector. This vector is called a “feature vector” or an “embedding”. Then, the decoder tries to upsample this feature vector so that the output of the decoder approximates the original signal. Essentially, what happens is the higher-dimensional signal is compressed to a lower-dimensional 1D signal. The space this signal lies in is called the “latent space”. Then, by decoding, a new image is reconstructed. In this process, only the dominant features get the chance to reside in the embedding. The length of this embedding becomes a hyperparameter of the training process.
What are the uses of Autoencoders
Becuase of this architecture, autoencoders have got superpowers such as
- Compress Data
- Denoise Data
- Find Outliers
- Do Inpainting
- With some modifications, autoencoders can be used as generative models
What’s the difference between Autoencoder and other Encoder-Decoder Architectures?
We know that the simplest way of copying a signal is to duplicate the signal. However, autoencoders are capable of reconstructing the original signal while preserving only the dominant features of the signal.
In autoencoders, the input and output domains are the same. Autoencoders are a subset of the Encoder-Decoder model. Now, you might wonder if there are Encoder-Decoder architectures with different input and output domains. Yes, there are. However, those encoder-decoder architectures are not considered as autoencoders. “Neural Machine Translation” (https://en.wikipedia.org/wiki/Neural_machine_translation) is an example of such architectures.
Autoencoders can also be classified into many categories depending on the context and the use of the domain.
- Autoencoding models: simplest type of autoencoder model
2. Contractive autoencoder: The type of models which are resilient to the small changes in the input. This is achieved by adding a regularisation term to the training objective.
3. Convolutional autoencoder (CAE): contains Convolutional layer inside encoder and decoder. Mostly used in autoencoder .
4. Sparse autoencoder: There is an added constraint on the encoding process. Here, the encoder network is trained to produce sparse encoding vectors, which have many zero values. This forces the network to identify only the most important features of the input data.
5. Denoising autoencoder: This type of autoencoder is designed to learn to reconstruct an input from a corrupted version of the input.
6. Variational autoencoders (VAE): Variational autoencoders are a type of generative model that learns a probabilistic representation of the input data. A VAE model is trained to learn a mapping from the input data to a probability distribution in a lower-dimensional latent space, and then to generate new samples from this distribution. VAEs are commonly used in image and text generation tasks.
7. Video Autoencoder: Video Autoencoder have been introduced for learning representations in a self-supervised manner. For example, a model was developed that can learn representations of 3D structure and camera pose in a sequence of video frames as input (see Pose Estimation). Hence, Video Autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. This autoencoder type can be used for camera pose estimation and video generation by motion following.
8. Masked Autoencoders (MAE): A masked autoencoder is a simple autoencoding approach that reconstructs the original signal given its partial observation. A MAE variant includes masked autoencoders for point cloud self-supervised learning, named Point-MAE. This approach has shown great effectiveness and high generalization capability on various tasks, including object classification, few-show learning, and part-segmentation. Specifically, Point-MAE outperforms all the other self-supervised learning methods
Read more at: https://viso.ai/deep-learning/autoencoder/
The loss function of an autoencoder
The primary loss function employed is the reconstruction loss, which measures the disparity between the model’s input and output. This loss is calculated using various methods such as mean squared error, binary cross-entropy, or categorical cross-entropy, depending on the type of data being reconstructed. For the time being, let’s take MSE as the loss function.
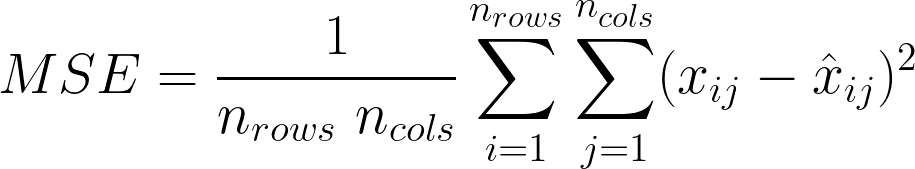
Implementing a Convolutional autoencoder in Pytorch
Since we are dealing with a problem in the image processing domain, it is ideal to use a Convolutional Autoencoder. Here’s how you can implement a CNN Autoencoder by yourself.
For the dataset, I used the Low Light Image (LOL) Dataset. This dataset contains RGB images with a resolution of 600x400. (I applied a transform for the dataset to crop the batch to 200x200 from the top left corner.) Therefore, it is better if you can use a CNN architecture like VGG or ResNet that works well with images within the same resolution range. (VGG and ResNet are trained on ImageNet with images of resolution 224x224).
# Define the CNN autoencoder model
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# Encoder layers
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
)
# Decoder layers
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid(),
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xI tried using different architectures; for example, I used VGG as the encoder and ResNet as the decoder. I experimented with various hyperparameters such as epochs and the size of the feature vector. Below is a summary of the results that I obtained.
My attempts and the results that I got
Attempt 1

Encoder : MNIST Dataset architecture
Decoder : MNIST Dataset Architecture
Size of feature vector : 8
Loss criterion : MSE(dark_reconstructed, bright)
Conclusion : The images appear blocky and pixelated. While the autoencoder attempts to reconstruct them, the results are not satisfactory. I want to determine whether this image has been reconstructed correctly.
Attempt 2

Encoder : MNIST Dataset architecture
Decoder : MNIST Dataset Architecture
Size of feature vector : 8
Loss criterion : MSE(bright_reconstructed, bright)
Conclusion : The images are pixelated. We might need to transition to a new architecture. This current architecture was based on denoising images from the MNIST dataset, which contains images with a resolution of (200x200). I’ve decided to utilize an architecture such as VGG or ResNet and increase the size of the feature vector.
Attempt 3
Encoder : MNIST Dataset architecture
Decoder : MNIST Dataset Architecture
Size of feature vector : 8
Result : I ran into a RAM crash. I implemented the architecture in reverse order, resulting in a RAM crash.
Attempt 4 :
Epochs were kept as a constant thought the process (like 40)
Attempt 4 A :


Here, I aimed to make a better decision for image translation. Since the Attempt 4 architecture was good enough for compression, I wanted to teach the model both compression on one hand and domain translation on the other hand. However, the results were not satisfactory.
loss = MSE(bright_constructed, bright) + MSE(dark_construced, bright)
Attempt 4 B:

Then I trained the same architecture keeping the loss criterion as follows.
loss = MSE(dark_constructed, bright)
Attempt 5 :
Encoder : VGG Model architecture
Decoder : VGG Model Architecture
Size of feature vector : 128
Here, I wanted to know how the results would be if I used bright images as the input and see how much the model can learn about the compression.
Result : Got reasonably good results for clean Reconstructed

Attempt 6 :
Here, I changed the architecture to ResNet; however, it also did not yield promising results.
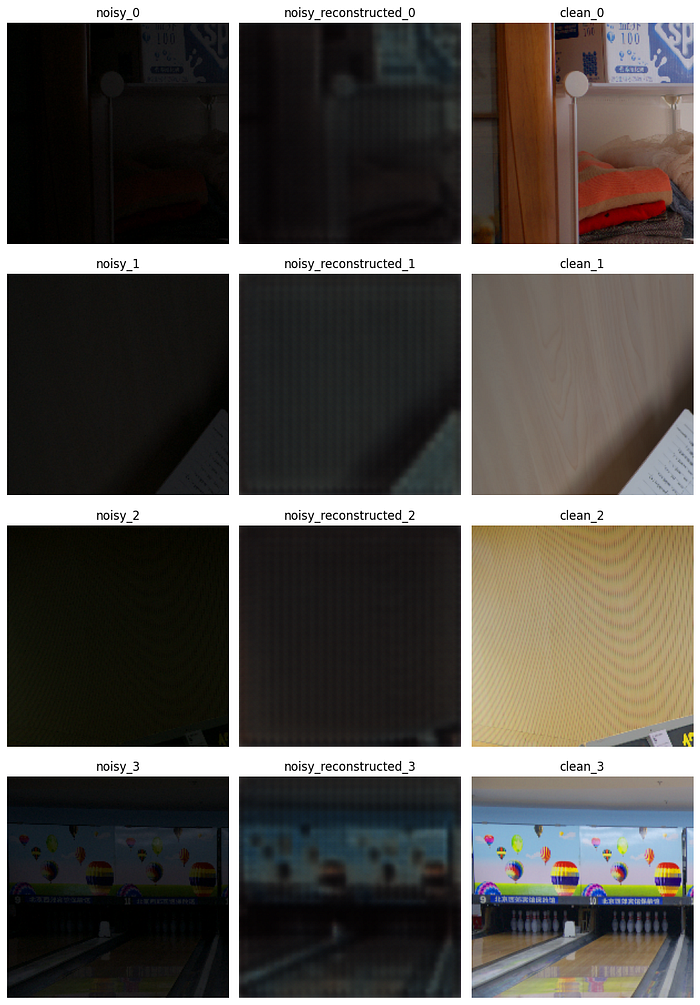
CONCLUSION ON USING CONVOLUTIONAL AUTOENCODER
According to my experimentation, the best results I got were from Attempt 4 which were considerably appealing although they were not perfect.
Variational Autoencoder
After searching for a better solution for image enhancement, I stumbled upon Variational Autoencoder. This article provides an in-depth explanation from theory to implementation: [Variational Autoencoder Demystified with PyTorch Implementation](https://towardsdatascience.com/variational-autoencoder-demystified-with-pytorch-implementation-3a06bee395ed).
The embedding space of an autoencoder is discontinuous: you can take an embedding of a 3, modify it just a tiny bit, and end up with a completely different number, or even something that does not resemble a number at all. Why? Because in our training, we use a loss that does not enforce any particular structure in the embedding space. So, the network finds the one that happens to solve our problem best, without considering any constraints regarding the structure of the space.
In more formal terms, we can say that the autoencoder learns a mapping between our images and the embedding space. It does not learn the distribution of the data in the embedding space.
This problem can be solved by other algorithms, for example, the so-called Variational Autoencoders (VAEs). They learn to project our points into an embedding space that has much more structure than a simple autoencoder. VAEs are proper generative models, in that they learn to represent the distribution of the dataset, and therefore their embedding space is much more regular and more suited for data generation.
REFERENCES
